Ogni giorno gli strumenti di monitoraggio generano una mole ingente di alert, ma molti di questi non segnalano vere minacce: sono falsi positivi. Un certo livello di ridondanza è fisiologico, ma quando il numero diventa eccessivo si crea il fenomeno della alert fatigue: più rumore, meno attenzione, tempi di risposta rallentati e priorità confuse.
In questo scenario il rischio è duplice. Da un lato, i team di Security Operations del provider MDR faticano a distinguere i segnali critici in mezzo al rumore, con il pericolo concreto di trascurare gli incidenti davvero importanti. Dall’altro, l’eccesso di falsi positivi ricade anche sul cliente finale, che si trova sommerso da avvisi ridondanti e costretto a lavorare più del necessario, proprio in un’area che un servizio MDR dovrebbe invece sollevarlo dal gestire.
Il paradosso è chiaro: più si lavora, meno si vede ciò che conta davvero. L’attenzione si disperde e il valore che un MDR dovrebbe garantire — rapidità, efficacia e affidabilità — rischia di essere compromesso.
Perché succede e come nasce l’“alert fatigue”
1 - Regole troppo generiche e poco contestualizzate
Molti falsi positivi derivano da regole di soluzioni tecnologiche di terze parti che, pur essendo plausibili, sono pensate per operare in contesti molto eterogenei; per questo non tengono conto del contesto specifico. Una detection progettata per adattarsi a qualsiasi ambiente finisce così per attivarsi anche dove non serve.
Un esempio sono gli EDR tradizionali: strumenti oggi imprescindibili per la sicurezza, ma spesso progettati con logiche di tipo black box. Forniscono regole predefinite pensate per adattarsi a diversi contesti, ma raramente offrono trasparenza sulle modalità di rilevamento. Questo approccio li rende talvolta troppo generici, limitando le possibilità di analisi avanzata e impedendo agli analisti più esperti di analizzare e validare gli allarmi nei tempi migliori.
Quando mancano informazioni chiave come chi, dove, quando e quanto è rilevante, ogni segnale viene trattato come critico per default.
2 - Mancanza di visibilità centralizzata
Molti servizi MDR si basano su un’ampia gamma di strumenti: endpoint, sonde network, cloud, log management, threat intelligence e così via. Se ciascun tool genera alert in modo indipendente, il risultato è un proliferare di duplicati, incongruenze e notifiche che non comunicano tra loro. A questa frammentazione si aggiunge un ulteriore ostacolo: ogni strumento “parla la propria lingua”. Senza una vista unificata, l’analista deve ricostruire manualmente il quadro complessivo, come se stesse componendo un puzzle con pezzi sparsi e incompleti.
Per evitare questo scenario servono tecnologie capaci di correlare eventi e segnali, provenienti da fondi differenti, in un unico ambiente. Solo così diventa possibile distinguere il rumore dagli eventi critici e avere una visione chiara e coerente delle minacce.

3 - Triage troppo manuale (e poca automazione)
Quando gran parte degli alert viene verificata manualmente, gli analisti sprecano minuti preziosi su eventi benigni e il backlog cresce. La differenza la fanno tecnologie che filtrano e aggregano i segnali da fonti diverse e leggono il contesto prima di allertare, applicando IOC e BIOC contestualizzati.
Su questa base, l’automazione del Tier 1 può anche eseguire azioni di contenimento sicure e tracciate — per esempio disabilitare o bloccare un utente e revocare sessioni, isolare un endpoint dalla rete, mettere in quarantena un file e aggiornare regole di firewall — riducendo i tempi di risposta senza togliere controllo agli analisti.
4 - Regole e procedure che non evolvono con minacce e infrastruttura
Le minacce cambiano rapidamente e le infrastrutture dei clienti anche: nuovi servizi, migrazioni cloud, identità e processi che si trasformano. Se le regole restano ferme, il rumore cresce.
Serve un approccio di detection engineering continuo: aggiornare IOC e BIOC, ricalibrare soglie e modelli comportamentali, validare e sostituire periodicamente le detection in base alle TTP più recenti e all’evoluzione dell’ambiente. Così le regole restano allineate sia agli attaccanti sia all’operatività reale, riducendo i falsi positivi senza perdere copertura.
Chi paga il prezzo dell’“alert fatigue”?
All’inizio a soffrire è il provider MDR. Il Tier 1 passa ore a scremare segnalazioni incerte, la velocità di risposta cala e l’energia mentale si consuma su verifiche ripetitive. Il Tier 2/Incident Response Team deve rincorrere pezzi di contesto sparsi tra strumenti diversi: quando il rumore è alto, le correlazioni utili si perdono e le indagini si allungano. Il Security Operations Manager, stretto dalle SLA, vede crescere stress e turnover nel team. Così, dentro il provider MDR, la fiducia negli allarmi si erode e il tempo si sposta dalla prevenzione alla gestione del caos.
Questo impatto rimbalza inevitabilmente sul cliente. Un flusso eccessivo di avvisi lo costringe a:
- gestire troppe segnalazioni,
- sottrarre tempo alle attività strategiche,
- subire escalation inutili,
- vedere aumentare i costi indiretti,
- fare lavoro extra proprio dove l’MDR dovrebbe alleggerire.
In breve: l’alert fatigue è un moltiplicatore di inefficienza, che riduce l’efficacia del servizio e scarica sul cliente un carico ulteriore.
La strategia di Certego
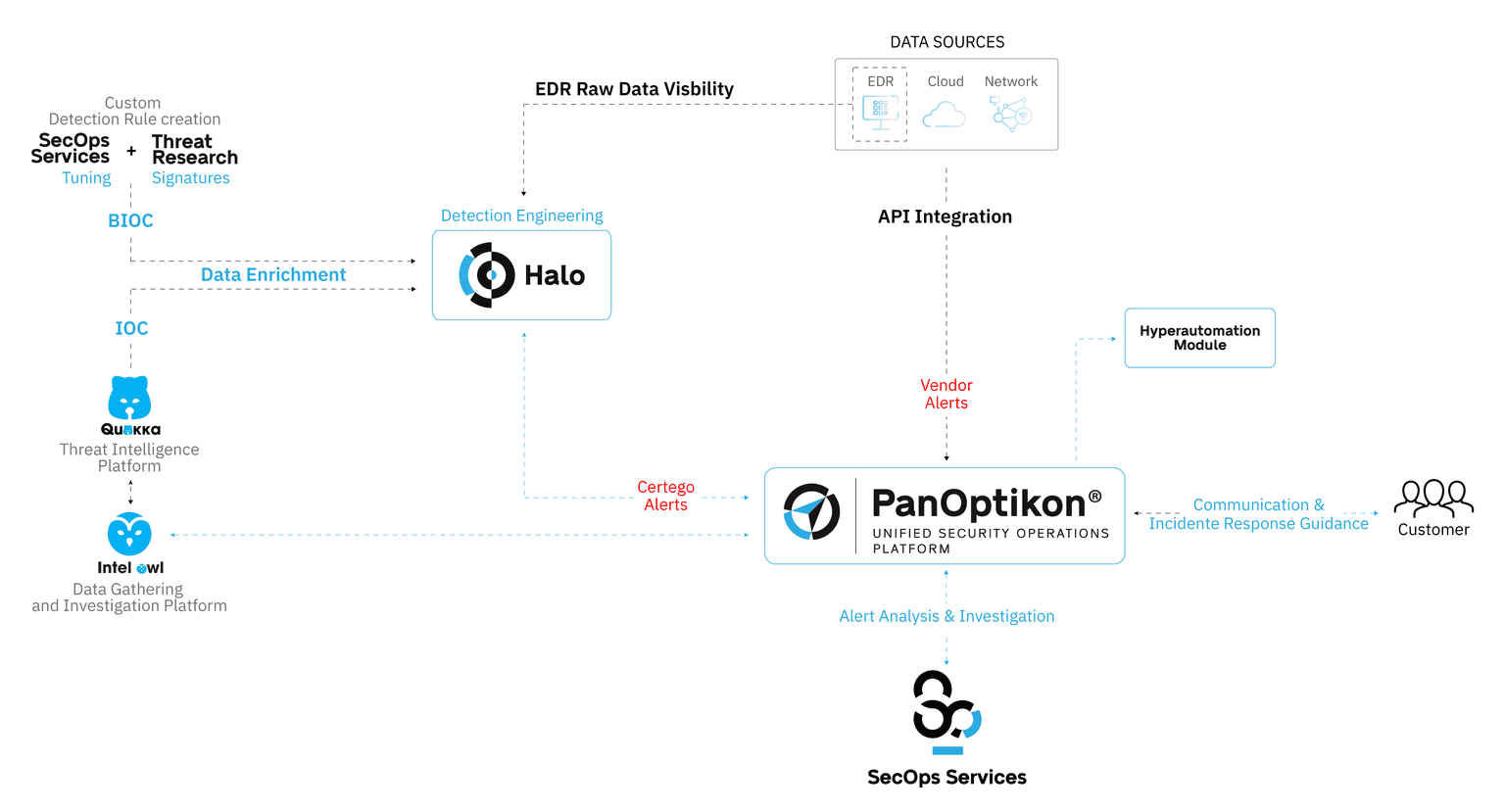
Ridurre i falsi positivi non significa “silenziare” la sicurezza, ma raffinare il segnale: non allertare di meno, bensì allertare meglio. Per questo in Certego abbiamo sviluppato un ecosistema applicativo proprietario, pensato per garantire visibilità completa, correlazione avanzata degli eventi e controllo totale delle tecnologie, senza vincoli di terze parti:
-
PanOptikon®: la piattaforma unificata di Security Operations che integra tutte le attività di SecOps, dalla visibilità sugli ambienti IT alla gestione degli incidenti end-to-end, con procedure basate sul framework NIST e reportistica conforme alle normative.
-
Halo: sviluppata per gli analisti di Certego, offre una visibilità avanzata sui dati telemetrici degli endpoint e supera le logiche black box dei tradizionali EDR. Permette di creare regole di detection personalizzate e di correlare molteplici eventi in un unico allarme, riducendo i falsi positivi e i carichi di lavoro.
-
Threat Intel (Quokka e IntelOwl): le piattaforme di Certego per arrichire e validare i dati di threat intelligence, raccogliendo informazioni da honeypot, sensori, dark web e fonti di info-sharing, per trasformare i segnali in verdetti affidabili e contestualizzati.
In questo modo il valore dell’MDR non si misura sulla quantità di alert, ma sulla loro qualità: meno rumore, più sicurezza, più velocità.
Il beneficio è concreto: tempi di risposta più rapidi, meno stress sul team, meno escalation inutili, più incidenti reali riconosciuti in tempo. Questo approccio ci permette di garantire un servizio MDR sempre aggiornato, personalizzabile e realmente efficace, senza compromessi.